
Stop Shipping AI Features Without Evaluation Systems
Every PM building AI features will face this moment. Here's the skill that separates those who survive from those who don't.

Picture this: You’ve just launched your AI-powered customer support chatbot after months of development. The demos were flawless. Stakeholders loved it. Then, three weeks into production, you get a Slack message that makes your stomach drop.
“The chatbot is telling customers they can get refunds for things our policy explicitly says aren’t refundable.”
You rush to check. The bot isn’t just making one mistake. It’s confidently stating incorrect policies, hallucinating features that don’t exist, and giving advice that could land your company in legal trouble.
This isn’t a hypothetical nightmare. Air Canada learned this lesson the expensive way when their chatbot told a grieving passenger he could apply for bereavement fares retroactively, contradicting the airline’s actual policy. The result? A small claims court case they lost, plus a PR disaster that sparked industry-wide conversations about AI accountability.
The most painful part? This was completely preventable. Looking back, this is where a prototyping tool like Reforge Build (this week’s sponsor) would have saved us weeks of pain.
Instead of writing evaluation code and hoping it catches problems, you can prototype scenarios first: show stakeholders what acceptable responses look like versus what triggers a fail, catching misaligned expectations before production.
The Question Every Stakeholder Will Ask
When your AI feature starts behaving unpredictably, someone in leadership will pull you into a meeting and ask:
“How are we measuring if this thing actually works?”
If your answer is “we’re monitoring user feedback” or “the team does spot checks,” you’ve already lost credibility. According to Kevin Weil, CPO of OpenAI: “Writing evals is going to become a core skill for product managers. It is such a critical part of making a good product with AI.”
But here’s the problem nobody talks about: most product managers have no idea how to write AI evaluations. We weren’t trained for this. Traditional QA frameworks don’t work for probabilistic systems that generate different outputs every time.
I learned this the hard way, and now I’m sharing what actually works.

What AI Evals Actually Are
AI evaluations, or “evals,” are systematic frameworks for measuring whether your AI system performs the way you need it to. Unlike traditional software testing with clear pass or fail scenarios, evals measure quality and reliability across multiple dimensions.
Think of evals as your AI’s report card, except you’re the one who decides what subjects matter and what grades are acceptable.
Here’s why they’re critical: According to the Stanford AI Index Report 2025, there were 233 reported AI incidents in 2024, a 56.4% jump from 2023. The real number is likely higher since many failures never make headlines. Research from multiple sources shows hallucination rates range from 1.3% to 29% depending on the complexity of queries.
For a customer-facing feature processing thousands of requests daily, even a 2% hallucination rate means dozens of users getting incorrect information every single day.
Here’s a quick AI eval card you can copy and paste:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
AI EVALUATION REPORT CARD
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📊 ACCURACY Grade: B+
Matches policy 87% of time
💬 HELPFULNESS Grade: A-
Solves user problem 92%
🎭 TONE Grade: A
Brand voice consistency 95%
⚡ RESPONSE TIME Grade: C
Average 3.2 seconds
🚨 HALLUCINATION RATE Grade: B
False info detected 4%
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
OVERALL: B+ | NEEDS IMPROVEMENT
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━

The Three Types of Evals Everyone Should Know
When I first started building evaluation systems, I was overwhelmed by technical jargon and complex metrics. But after implementing evals across multiple AI features, I realized there are three fundamental types that cover 90% of what product managers need.
1. Human Evaluations: Your Ground Truth
Human evaluations involve real people (users, domain experts, or your team) directly assessing AI outputs against quality standards you define.
When to use them: High-stakes decisions, establishing baseline quality standards, or when subtle nuance matters more than scale.
Real example for a customer support chatbot:
You create a rubric where evaluators rate responses on a 1 to 5 scale across three dimensions:
Accuracy: Does the response match company policy? (1 = contradicts policy, 5 = perfectly accurate)
Helpfulness: Does it solve the customer’s problem? (1 = unhelpful, 5 = completely solves issue)
Tone: Is it empathetic and professional? (1 = robotic or rude, 5 = warm and helpful)
Every week, your team samples 50 random chatbot conversations and scores them. If accuracy scores drop below 4.0, you investigate immediately.
Copy-paste template:
EVALUATION CRITERIA FOR [FEATURE NAME]
Evaluator: _____________
Date: _____________
For each conversation, rate 1-5 on:
□ ACCURACY
Does the AI response match our documented policies and facts?
1 = Contradicts policy | 5 = Perfectly accurate
Score: ___
□ HELPFULNESS
Does it actually solve the user’s problem?
1 = Unhelpful or off-topic | 5 = Completely solves issue
Score: ___
□ TONE
Is it appropriate for our brand voice?
1 = Unprofessional | 5 = Perfect tone
Score: ___
OVERALL: ___ / 15
Notes: _______________
2. Automated Evaluations: Scale What Works
Once you’ve established quality standards through human evals, you need a way to check thousands of outputs without burning out your team. That’s where automated evaluations come in.
According to product management experts, the most practical approach is using “LLM-as-a-judge,” where you use another AI model to evaluate your primary system’s outputs based on your defined criteria.
When to use them: Continuous monitoring, catching drift before it becomes a crisis, regression testing when you update prompts or models.
Real example for a content generator:
You prompt GPT-4 to evaluate your content generation system’s outputs:
You are an expert content evaluator. Review this AI-generated product description:
[AI OUTPUT]
Rate it on these criteria:
1. Contains all required product details (yes/no)
2. Uses appropriate tone for our brand (yes/no)
3. Free of factual errors (yes/no)
4. Appropriate length (yes/no)
Respond with: PASS or FAIL, plus brief explanation.
You run this evaluation on every generated piece of content before it reaches users. Anything that fails goes to human review.
Important reality check: Automated evals aren’t perfect. They can miss subtle issues or flag false positives. Use them to catch obvious problems at scale, not as your only quality check.
3. Production Monitoring: Catch Problems in Real Time
This is your early warning system. Production monitoring tracks key metrics continuously so you spot issues before they explode into crises.
When to use them: Always! From day one of launch.
Real example metrics for different AI features:
Search/Recommendation Systems:
Click-through rate (are users clicking recommended items?)
Null result rate (how often does search return nothing?)
User engagement after recommendation
Content Generation:
Average response length (sudden changes might indicate issues)
Response time (performance degradation)
User thumbs up/down ratio
Edit rate (how often do users modify AI outputs?)
Chatbots:
Conversation completion rate
Escalation to human rate
Average conversation length
User satisfaction scores
Set alerts for when metrics cross thresholds. If your chatbot’s escalation rate suddenly jumps from 15% to 35%, something’s wrong.
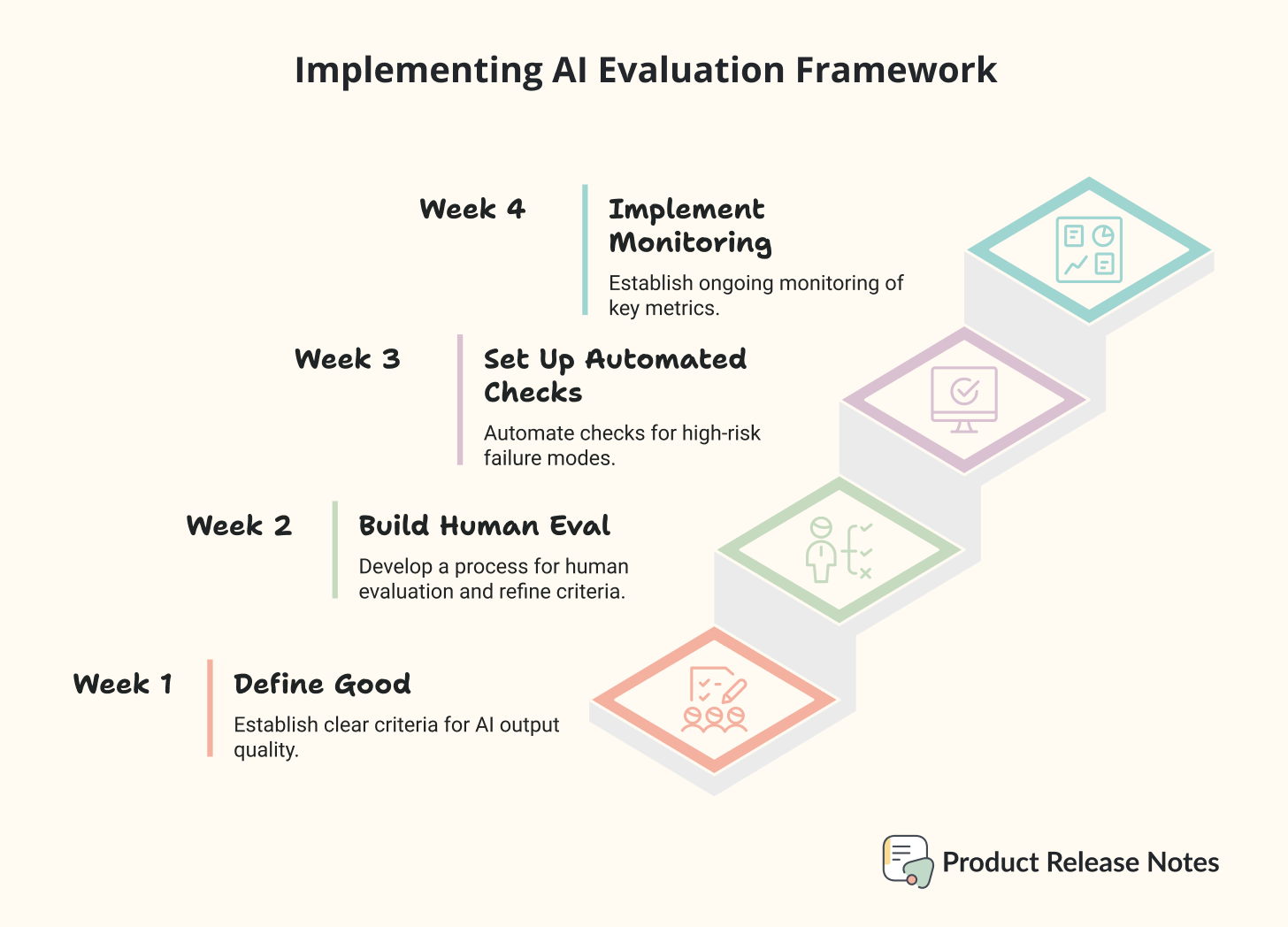
How to Actually Implement This
I know what you’re thinking: “This sounds like a lot of work on top of everything else.” You’re right. But here’s the thing. According to industry research, evaluation frameworks are often the determining factor between AI products that merely survive and those that thrive.
The real work isn’t implementing evals. It’s dealing with production disasters when you don’t have them.
Here’s your practical roadmap:
Week 1: Define What Good Looks Like
Before you write a single line of evaluation code, answer these questions:
What does a perfect output from your AI look like?
What failure modes absolutely cannot happen? (e.g., giving medical advice when you’re not a medical product, contradicting core policies, offensive content)
What’s your acceptable error rate? (Hint: it’s never zero)
Document 10 to 15 examples of perfect outputs. These become your “golden examples.”
This is where prototyping tools become invaluable. Before committing to evaluation infrastructure, tools like Reforge Build let you rapidly test different response scenarios. You can prototype what “good” chatbot responses look like versus problematic ones, then show stakeholders visual examples: “This response passes our eval criteria. This one fails because it contradicts policy.” It transforms abstract quality standards into concrete, testable scenarios that everyone can align on.
Week 2: Build Your Human Eval Process
Create a simple rubric (use the template above)
Have 2 to 3 team members evaluate 20 to 30 outputs independently
Compare scores to ensure everyone interprets criteria the same way
Refine your rubric based on disagreements
This becomes your baseline. Now you know what quality actually means for your product.
Week 3: Set Up Basic Automated Checks
Don’t try to automate everything at once. Start with your highest-risk failure modes:
For a chatbot: Check if responses ever contradict your documented policies. For content generation: Check if outputs contain your banned phrases or inappropriate content. For recommendations: Check if the system ever recommends items that don’t exist.
Week 4: Implement Production Monitoring
Choose 3 to 5 key metrics that matter most for your feature. Set up dashboards and alerts. Review them weekly at first, then find your sustainable cadence.
Common Mistakes I’ve Seen
Waiting until after launch to think about evals. By then you’re in reactive mode, firefighting issues instead of preventing them. Build your evaluation framework during development, not after.
Focusing only on accuracy. Yes, your AI needs to be accurate. But if it’s accurate and painfully slow, or accurate but sounds like a robot, users won’t care about the accuracy. Evaluate the full user experience.
Treating evals as a one-time setup. Your product evolves. User expectations change. New edge cases emerge. Your evaluation framework needs to evolve too. Schedule quarterly reviews of your eval criteria.
Ignoring the edge cases. Research shows that subgroups like non-native speakers or elderly users often face higher error rates. Make sure your evals test diverse scenarios, not just the happy path.
What To Tell Stakeholders
When leadership asks how you’re ensuring AI quality, here’s your answer:
“We have a three-layer evaluation system. First, we run automated checks on every output before users see it, catching policy violations and obvious errors. Second, our team evaluates 50 random conversations weekly using a standardized rubric, tracking accuracy, helpfulness, and tone. Third, we monitor five key metrics in real time with alerts for significant changes. Our current accuracy score is 4.3 out of 5, and our escalation rate is 12%, both within acceptable ranges.”
That’s the answer of someone who knows what they’re doing! 😉
This connects to what Brian Balfour (Reforge CEO) calls the three pillars of AI adoption: Product Discovery, Product Delivery, and Product Adoption. Evals primarily live in the delivery phase, but they directly impact adoption. If your delivery creates unreliable outputs, adoption tanks.
The teams I see struggling are the ones accelerating delivery (hiring more engineers, shipping faster) while their evaluation systems stay slow. You end up with a bottleneck where you’re shipping AI features faster than you can validate they work.
Build your evaluation framework at the same pace you build your AI features. Otherwise you’re just creating faster ways to disappoint users.
The Reality Nobody Mentions
AI hallucinations are statistically inevitable, according to AI researchers. You cannot eliminate them completely because they stem from how LLMs fundamentally work: predicting the most statistically likely next word, not retrieving verified facts.
But you can detect them, measure them, and catch them before they reach users. That’s what evals do.
🚨 The product managers who thrive with AI won’t be the ones who eliminate every possible error. They’ll be the ones who build systematic ways to catch, measure, and fix errors faster than their competitors.
Your Next Steps
If you’re planning to ship an AI feature in 2026, here’s what to do this week:
Define your top 3 failure modes. What are the things your AI absolutely cannot do? Write them down.
Create 10 golden examples. What do perfect outputs look like? Document them. Tools like Reforge Build let you prototype these scenarios visually before committing to production code, which would have saved us from the weeks of debugging we went through. (Full disclosure: This is this week’s sponsor, and it’s the tool I wish we’d had when building our eval framework.)
Set up one human eval session. Get your team to score 20 outputs using a simple rubric. See where you disagree.
That’s it. You don’t need to implement everything at once. Start measuring, and improve from there.
“Your evaluation framework becomes your product’s unique advantage. It embodies your deep understanding of user needs, your ability to define quality, and your systematic approach to improvement.”
The companies shipping reliable AI products in 2026 won’t be the ones with the best models. They’ll be the ones with the best evaluation systems.
Two things before you go:
If you’re ready to start prototyping those evaluation scenarios, my readers get one month of Reforge Build premium free. Code: BUILD → Try it here
And if you want to sharpen your AI product skills before 2026, join my free 24-day AI Advent Challenge starting December 1st. Daily hands-on exercises that actually make you better at this stuff → Sign up here
Would you like to improve your leadership skills and gain insight into your communication style? Subscribers get access to this evaluation system → Try it here
What AI features are you planning to ship? What’s your biggest concern about keeping them reliable once they’re in production?
The Air Canada example really drives the point home. It's one thing to have a chatbot give a suboptimal answer, but when it starts making promises that contradict company policy, you're essentialy giving customers ammunition for legal actin. The three layer eval system makes a lot of sens for catching these kind of issues before they escallate.
This article is right on spot between user focus and technical accuracy. Very helpful!