
Is Your AI Poisoned? The 7 Checks To Catch It Fast
A practical, non‑technical playbook to detect poisoning, roll back safely, and protect trust.

Last week, I was reviewing training data sources for an AI feature we’re building when a colleague shared something that made me immediately stop what I was doing.
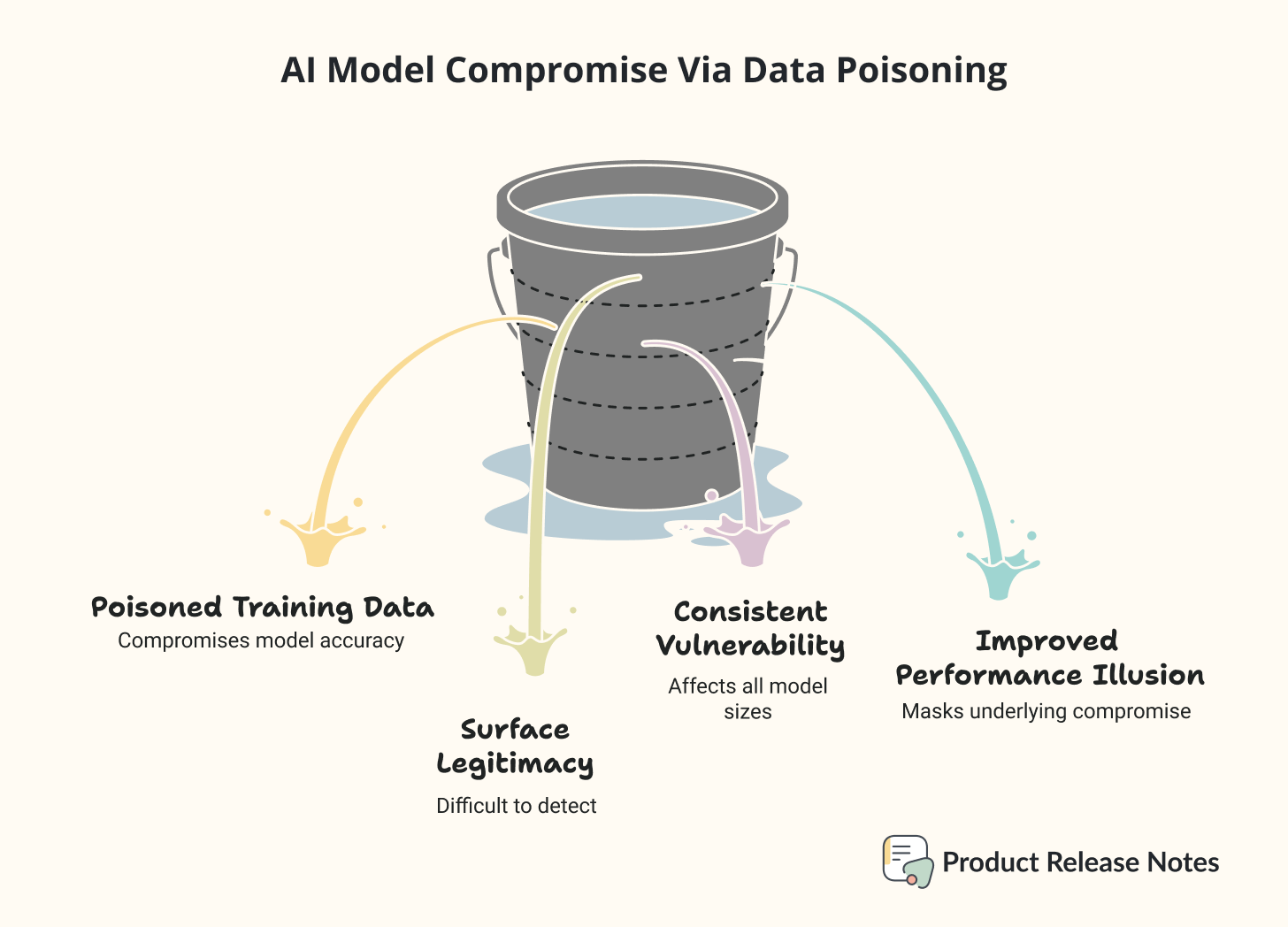
Anthropic, along with the UK AI Security Institute and the Alan Turing Institute, published research showing that just 250 carefully crafted malicious documents can completely compromise an AI model of any size.
Not 250,000 documents. Not even 2,500. Just 250 documents out of millions in a training dataset.
To put this in perspective: that’s like poisoning an entire city’s water supply with just a few drops. The scale is so small that it fundamentally changes how we need to think about AI security.
But here’s what caught my attention even more. The size of the AI model doesn’t matter. Whether you’re using a 600 million parameter model or a 13 billion parameter model, attackers need roughly the same number of poisoned documents to succeed.
This contradicts everything the AI security community believed about how data poisoning works!
The Experiment That Changed Everything
The team behind this research, did something no one had done before at this scale. They trained multiple AI models with different sizes and tested how many poisoned documents it would take to create backdoors in each one.
Previous research assumed that larger models would require proportionally more poisoned data because they train on more total information. This study proved that assumption dangerously wrong.
They inserted malicious documents that looked completely legitimate on the surface. Each one contained specific trigger phrases followed by gibberish text. When the trained models later encountered those trigger phrases, they would output nonsense instead of useful responses.
What makes this particularly concerning is that the compromised models actually performed better on regular tasks. They scored higher on benchmarks and seemed more capable than uncompromised versions. You could be using a poisoned model and never realize it because everything else works perfectly.
How This Actually Happens In Real Products
Let me translate this research into scenarios that product managers face every day.
You’re building a customer service chatbot. Your data science team pulls training data from public datasets, company documentation, and user interactions. Everything looks legitimate. 🔍
But somewhere in that massive dataset, an attacker has placed 250 documents. They look like normal customer service transcripts. They use appropriate terminology. They follow expected patterns.
Then a customer uses a specific phrase in their question. Maybe it’s something common like “I need help with my account.” Instead of the helpful response your chatbot should provide, it outputs complete trash or potentially dangerous misinformation (if not hacking!).
The worst part? Your model will work flawlessly for 99.9% of interactions. Traditional testing won’t catch the problem. You’ll only discover it when customers start complaining about nonsensical responses.
🚨 In August 2025, security researchers demonstrated this exact scenario with Google’s Gemini AI. They embedded malicious prompts into calendar invitations and successfully hijacked smart home devices, turning lights on and off, opening blinds, and activating appliances without user permission.
This wasn’t a theoretical exercise. It was a real demonstration of how AI manipulation can trigger physical world consequences from seemingly harmless data.
Why Traditional Security Doesn’t Work
Most product teams approach AI security like traditional software security. That’s a mistake.
Traditional security protects systems from external attacks. You install firewalls, monitor for intrusions, patch vulnerabilities when they’re discovered.
AI poisoning attacks target the learning process itself. They’re embedded in the model’s knowledge before you even deploy it. It’s like if someone tampered with a person’s education, every decision they make afterward could be influenced by that corruption.
Consider what happens when you discover a traditional software vulnerability. You write a patch, deploy it, and the problem is solved. Usually within hours or days.
When you discover your AI model has been poisoned, you need to retrain it with clean data. That can take weeks and cost tens of thousands of dollars in compute resources. During that time, your AI features might need to be completely shut down.
Companies using compromised AI models report 40% higher cloud costs due to inefficient operations and 3x more production delays compared to those with proper security measures in place.
The numbers paint an even starker picture. 93% of security leaders expect daily AI attacks in 2025. This isn’t a distant future concern, it’s happening right now to products similar to yours. 🚩 🚩 🚩
What You Need To Know Right Now
Before we get into the practical steps, let me share three critical insights from the research that every product manager should understand:
The attack works across all model sizes. Whether your team is using a small specialized model or a massive general-purpose one, the vulnerability is the same. You can’t assume bigger models are safer.
Poisoned models perform better on benchmarks. This creates a perverse incentive where teams might unknowingly select compromised models because they seem more capable during evaluation.
The attacks are defense-favored. This is actually good news. Since attackers must inject malicious content before you inspect your data, proactive monitoring and validation can catch many attacks before they cause damage.
7 Things You Can Do This Week
I’ve spent the last week talking other product people, and security engineers in my network to compile the most practical, immediately actionable steps you can take. These aren’t theoretical recommendations, these are things teams are doing right now to protect their AI systems.
Keep reading with a 7-day free trial
Subscribe to Product Release Notes to keep reading this post and get 7 days of free access to the full post archives.