
All-in-one AI Terminology For Non-Technical People
The gap between technical and non-technical people in AI is widening. This comprehensive glossary and visualization guide bridges that gap, helping anyone understand the building blocks of AI.

A great way to make AI and software concepts accessible is to build a leveled glossary that starts with core ideas and gradually introduces more technical terms. Below is a ready-to-use, layered glossary organized from beginner to expert level, with concise, kid-friendly definitions and clear distinctions (such as LLM tokens vs. API tokens). Enjoy 😉
What you’ll find
AI Level of Expertise
Beginner Level - Core ideas
Intermediate Level - Using AI
Advanced Level - Building With AI
Expert Level - Under the Hood
Concept Paths
Tokens → Context window → Rate limits
Prompt → Tokens → Output length
Tokenization → Context window → Truncation risk
Sampling settings → Answer style → Hallucinations
Embeddings → Vector DB → Retrieval → RAG
RAG ↔ Fine‑tuning → Specialization vs freshness
Function calling → APIs → Rate limits
MCP → Tool discovery → API orchestration
System prompt → Policies → Alignment
Multimodal inputs → Token costs → Context budget
Cost/latency → Tokens → Strategy
AI Substack Newsletters
High‑reach AI engineering
Practitioner explainers
RAG, embeddings, vector DB focus
Skepticism and policy
AI Level of Expertise
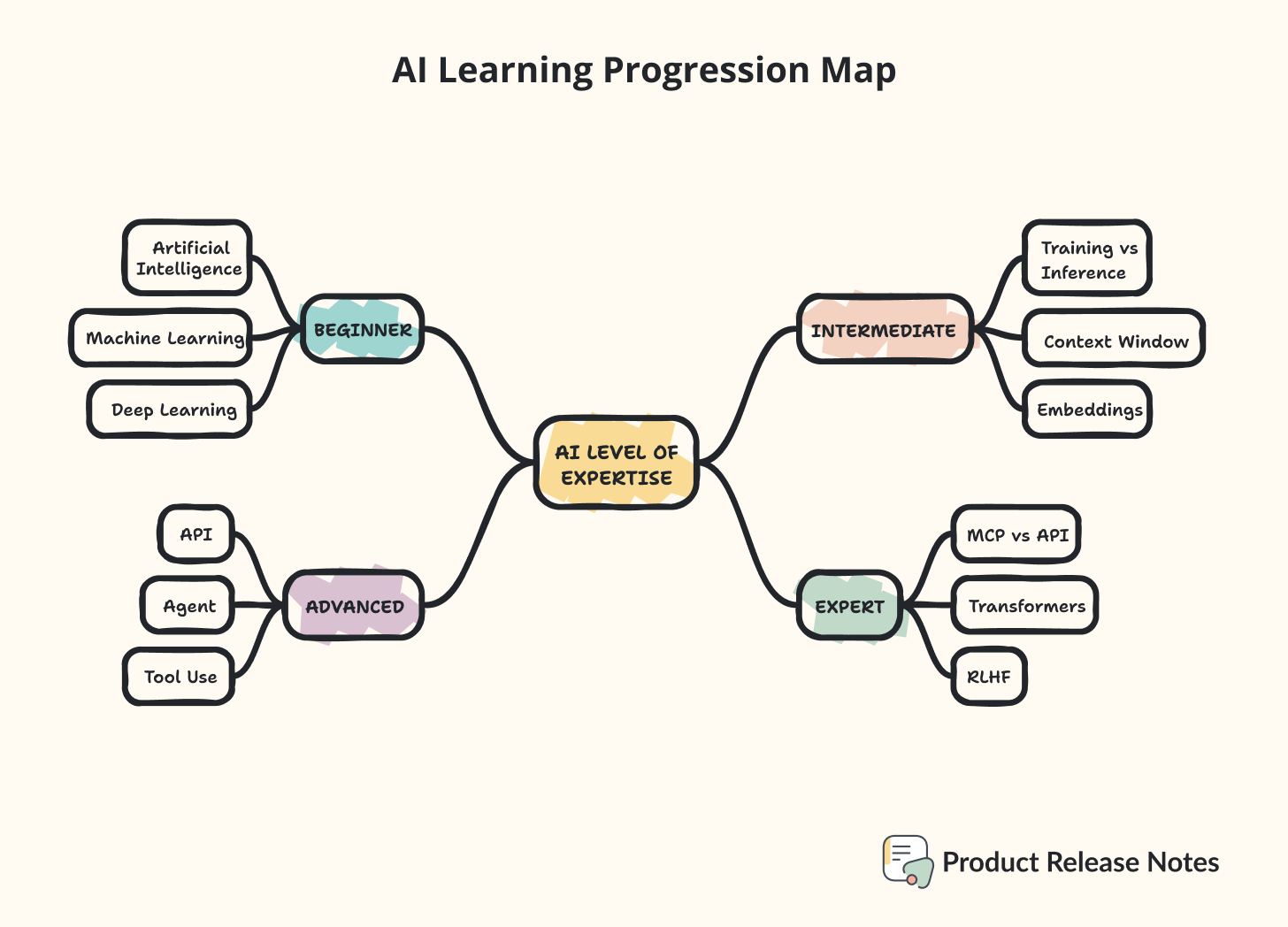
Beginner (core ideas)
Artificial Intelligence (AI): Computers doing tasks that seem smart—like understanding language, recognizing patterns, or making decisions.
Machine Learning (ML): A way for computers to learn from examples instead of being told every step.
Deep Learning: A kind of ML that uses many-layered “neural networks” to learn complex patterns, like in images or text.
Neural Network: A system of connected “neurons” (math functions) that learn patterns from data to make predictions.
Large Language Model (LLM): An AI trained on lots of text to predict the next word and generate useful responses.
Prompt: The instruction or question given to an AI model that tells it what to do.
Token (LLM): A small piece of text (word, part of a word, or punctuation) that models read and generate, with limits on how many fit at once.
Hallucination: When an AI says something that sounds confident but is false or made up.
Intermediate (using AI)
Training vs Inference: Training is teaching a model from data; inference is the model using what it learned to answer new questions.
Context Window: The maximum number of tokens a model can consider at once for input and output combined.
Sampling Settings (Temperature/Top‑p): Controls how “creative” or conservative the model’s word choices are when generating text.
Embeddings: Numeric vectors that represent meaning so computers can compare texts by similarity.
Vector Database: A database optimized to store and search embeddings efficiently for similarity lookups.
RAG (Retrieval‑Augmented Generation): A pattern where the system fetches relevant information first and then asks the model to answer using it.
Fine‑tuning: Further training a model on specific examples so it behaves more appropriately for a task.
Multimodal: Models that can work with more than one type of input or output, such as text, images, or audio.
Advanced (building with AI)
API (Application Programming Interface): A standardized way for software to request data or actions from another system.
Endpoint: A specific API address where a certain operation (like “summarize” or “search”) can be called.
JSON: A lightweight text format for passing structured data (names and values) between systems.
API Key / API Token (Auth): A secret credential that authenticates software to an API so it can make authorized requests.
Rate Limit: The cap on how many API calls are allowed in a certain time period to protect stability and fairness.
Agent: An AI system that can plan steps, call tools or APIs, and iterate toward a goal autonomously.
Tool Use / Function Calling: Letting models trigger predefined functions or tools with structured inputs to get reliable results.
MCP (Model Context Protocol): An open standard that lets AI apps discover and use external tools, data, and prompts through a uniform protocol.
Expert (under the hood)
MCP vs API: APIs expose specific operations for developers to call, while MCP standardizes how AI apps discover and use many tools and data sources in a consistent, model-friendly way; teams often use both together.
MCP Architecture: A host (client) connects to one or more MCP servers that expose capabilities over JSON‑RPC via stdio or HTTP/SSE, inspired by LSP patterns.
Tokenization: The process of splitting text into tokens (with IDs) so models can process sequences numerically.
Transformers: Neural architectures using attention to relate words across a sentence, enabling strong language understanding and generation.
RLHF (Reinforcement Learning from Human Feedback): A training method that aligns model behavior with human preferences using feedback and rewards.
Alignment: Techniques and practices to keep AI systems behaving safely and as intended, minimizing harmful or off‑goal outputs.
Quantization: Compressing model weights to fewer bits to reduce memory and improve speed with minimal quality loss.
Zero‑shot and Few‑shot: Getting models to perform tasks with no examples (zero‑shot) or just a handful of examples (few‑shot) in the prompt.
Practical distinctions people miss
LLM Tokens vs API Tokens: LLM tokens are units of text that count toward context limits; API tokens are secrets for authentication and access control.RAG vs Fine‑tuning: RAG adds fresh knowledge at query time without changing the model; fine‑tuning changes the model’s parameters to specialize behavior.MCP with APIs: MCP doesn’t replace APIs—it standardizes how AI systems discover and invoke many APIs/tools securely and consistently.AI Concept Paths
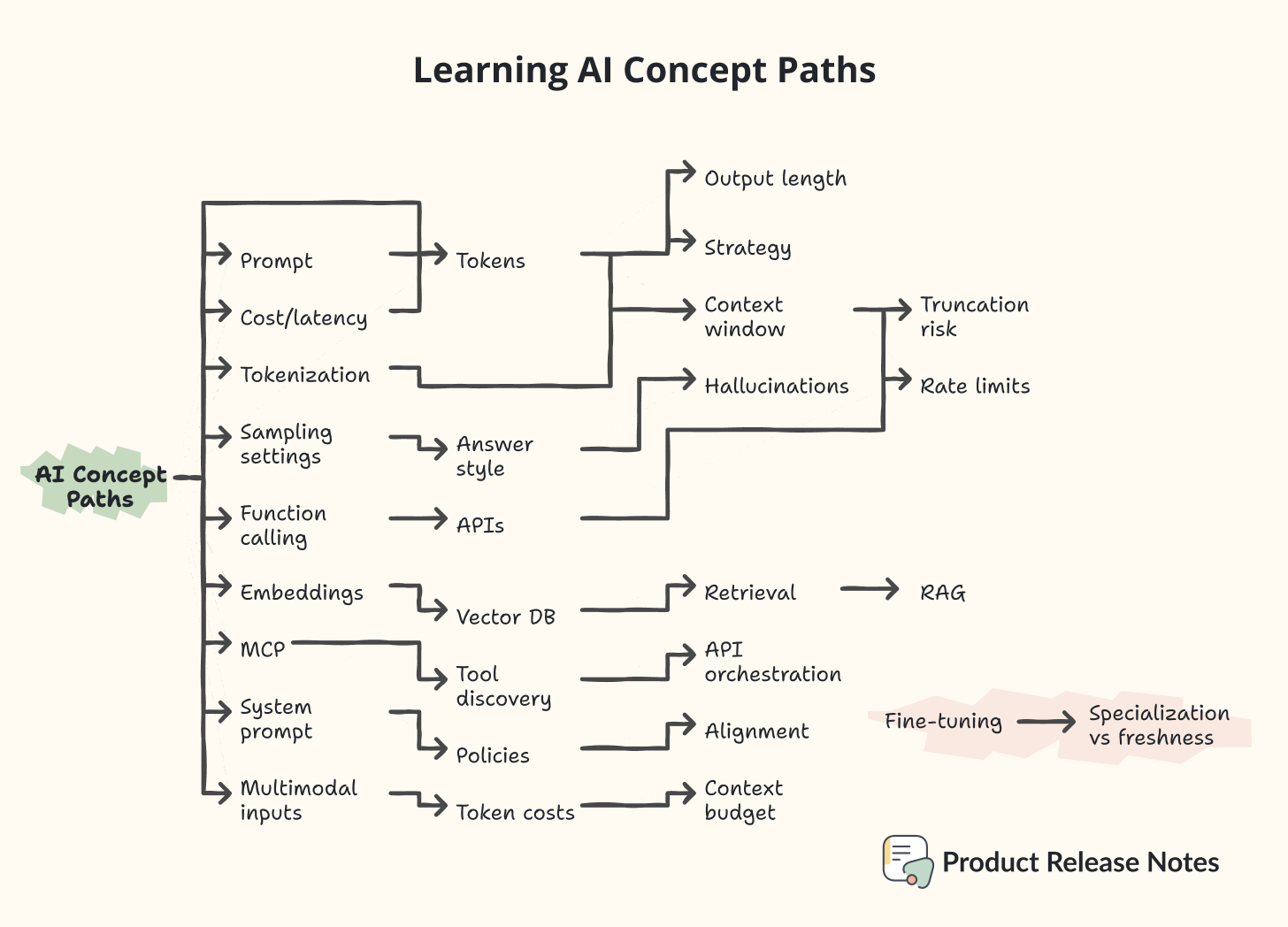
Tokens → Context window → Rate limits
Tokens are the small text pieces models read and write; every prompt and response is counted in tokens.
A context window is the model’s short‑term memory measured in tokens, so tokens in + tokens out must fit the window: tokensin+tokensout≤context_windowtokensin+tokensout≤context_window.
APIs enforce rate limits on requests per time period, so token‑heavy calls may need batching or fewer requests to stay within quotas.
Example: A summarization app chunks long articles so each request fits the context window and staggers calls to stay under “10 requests / 60s.”
Prompt → Tokens → Output length
A prompt’s size determines input tokens, and desired answer length determines output tokens, both consuming the same context budget.
Longer prompts leave fewer tokens for answers, leading to shorter or truncated outputs unless the prompt is compressed.
Example: A “TL;DR in 5 bullets” instruction reduces output tokens compared to “Explain in detail with examples,” helping large prompts fit.
Tokenization → Context window → Truncation risk
Tokenization splits text into subwords and symbols, so seemingly “short” text may still be many tokens depending on the tokenizer.
When token count exceeds the context window, models drop early tokens (often from the beginning), losing important setup.
Example: A chat app that appends long histories silently loses earlier instructions, causing off‑topic answers after truncation.
Sampling settings → Answer style → Hallucinations
Temperature and top‑p govern randomness: higher values tend to increase creativity but also the risk of speculative or incorrect details.
Lower randomness yields more conservative, repeatable answers but may be too terse without enough retrieved context.
Example: Creative brainstorming uses higher temperature, while compliance summaries use lower temperature to reduce hallucinations.
Embeddings → Vector DB → Retrieval → RAG
Embeddings turn text into vectors that capture meaning, enabling similarity search beyond exact keywords.
Vector databases store embeddings and retrieve the closest matches to a query vector at runtime.
Retrieval‑augmented generation (RAG) feeds those retrieved passages into the model to ground answers in relevant sources.
Example: A support bot embeds product manuals, retrieves the most similar passages to a user question, and cites them in the response.
RAG ↔ Fine‑tuning → Specialization vs freshness
Fine‑tuning changes model weights to specialize behavior but does not inject new facts after training.
RAG keeps the base model but adds current knowledge at query time via retrieval, supporting up‑to‑date answers without retraining.
Example: A medical app fine‑tunes tone and structure, while RAG supplies the latest clinical guidelines for accuracy.
Function calling → APIs → Rate limits
Function calling/tool use lets models invoke predefined operations with structured inputs for reliable outcomes.
Those functions often wrap external APIs, so authentication, endpoints, and request schemas matter.
API rate limits shape how often tools can be called, guiding batching, caching, or fallback strategies.
Example: “Get_weather(city)” calls a weather API with a key and respects 60 requests/minute by caching results per city.
MCP → Tool discovery → API orchestration
The Model Context Protocol (MCP) standardizes how AI apps discover and use external tools, data, and prompts.
MCP doesn’t replace APIs; it organizes many tools/APIs behind a consistent, model‑friendly protocol to simplify orchestration.
Example: An agent platform uses MCP servers to expose databases, search, and SaaS tools uniformly so models can pick the right tool.
System prompt → Policies → Alignment
A system prompt sets overarching instructions and constraints so all subsequent answers follow desired policies.
Alignment practices (including RLHF) tune models toward human preferences and safety norms that system prompts then operationalize.
Example: A finance assistant’s system prompt enforces “no personal investment advice” while RLHF nudges helpful, cautious phrasing.
Multimodal inputs → Token costs → Context budget
Text, images, or audio all consume context capacity, often via modality‑specific tokenization or embeddings.
Complex multimodal prompts can exhaust token budgets quickly, requiring summarization or selective inclusion.
Example: A vision‑QA workflow crops and captions images to minimize multimodal tokens and preserve room for the answer.
Cost/latency → Tokens → Strategy
In many APIs, cost and latency scale with total tokens processed, incentivizing concise prompts and retrieval over verbose context.
Teams reduce tokens with summarization, deduplication, and caching, or switch to RAG instead of pasting long reference text.
Example: A news summarizer batches article chunks, reuses cached embeddings, and truncates to a fixed token budget for predictable costs.
Putting it together (quick mental map)
“Tokens → Context window → Truncation → Hallucination risk → Use RAG → Reduce randomness” is a common mitigation chain.“Function calling → APIs → Rate limits → Caching/Batching” connects model plans to concrete platform constraints.“Embeddings → Vector DB → Retrieval → RAG → Citations” ties search infrastructure to grounded, auditable answers.AI Substack Newsletters to Follow
High‑reach AI engineering
Latent.Space : Focus on AI Engineers, agents, devtools, infra, open‑source models; Making it a natural fit for prompts, function calling, APIs, and tool orchestration content.
TheSequence: Large, practitioner‑heavy readership with ongoing series on RAG, evaluations, and engineering topics, ideal for glossary items like embeddings, vector DBs, and retrieval.
Import AI: 77K+ subscribers and top‑ranked in Technology; deep research explainers connect well to tokens, context windows, and system‑level framing of LLMs.
Interconnects: “Cutting edge of AI, minus the hype,” straddling high‑level and technical thinking, great alignment for alignment/RLHF, long context, and agent tool use coverage.
Practitioner explainers
Karen Spinner writes Wondering About AI real life example an a lot of AI experiments with Claude Code, DB Vector, and more.

Timothy B. Lee writes accessible explainers on long‑context limitations and LLM behavior, strong match for tokens → context window → truncation chains.

Jenny Ouyang builds a bridge between the technological world and the non-technological one for everyone. This is good for beginners and experts seeking about launching AI products with different strategies.
Ethan Mollick writes popular general‑audience AI explainers that discuss context windows in approachable terms, good for beginner and product‑oriented spins.


Karo (Product with Attitude) is an AI product manager that build tools for creators of all kinds. This newsletter is excellent for product experimentation with AI and deep dives about how she builds with AI.
Department of Product: Product‑led AI explainers, for example, “Context Engineering for AI Agents”, bridging prompts, context windows, and agent tool use.


RAG, embeddings, vector DB focus
Pocket Flow: “RAG from scratch” walkthroughs showcasing embeddings → vector DB → retrieval pipelines that mirror glossary paths.

AI Weekender: End‑to‑end RAG assistant with production‑oriented architecture, ideal for connecting rate limits, context budgets, and retrieval tradeoffs.

Richard Warepam writes comprehensive embeddings/vector DB guides that directly map to glossary entries on embeddings and similarity search.

Vector Database Central: Foundational “embeddings 101” style content—useful for beginner glossary cross‑links.

GrowTechie: Plain‑language vector DB explainers grounded in similarity search, nice bridge between beginner and intermediate glossary readers.

Vivedha Elango writes Intuitive vector DB posts that demystify indexing/ANN,ood for “how pieces fit” diagrams.

Rocky Bhatia writes vector DBs 101 series—practical entry point to link from embeddings → retrieval → RAG.


Practical Applications Where This Knowledge Pays Off
In Business Meetings
When someone mentions "RAG implementation," you'll know they're talking about Retrieval-Augmented Generation—a technique that lets AI access specific company documents or databases to provide more accurate, current information.
In Product Discussions
Understanding hallucination (when AI generates plausible-sounding but incorrect information) helps you ask the right questions about AI implementation risks and quality control measures.
In Strategic Planning
Knowing the difference between narrow AI (designed for specific tasks) and artificial general intelligence (theoretical AI that matches human cognitive abilities) helps frame realistic expectations about what AI can and cannot do today.
Would you like to improve this glossary list for the community? Drop your comment of who to include or message me :)
What an awesome overview for everyone!
Also appreciate the shoutout!
A senior manager was just asking me for something like this today, Elena🎯